On the Role of ViT and CNN in Semantic Communications: Analysis and Prototype Validation
early ViT-based semantic communications analysis with SDR prototype validation.
Abstract
Semantic communications have shown promising advancements by optimizing source and channel coding jointly. However, the dynamics of these systems remain understudied, limiting research and performance gains. Inspired by the robustness of Vision Transformers (ViTs) in handling image nuisances, we propose a ViT-based model for semantic communications. Our approach achieves a peak signal-to-noise ratio (PSNR) gain of +0.5 dB over convolutional neural network variants. We introduce novel measures, average cosine similarity and Fourier analysis, to analyze the inner workings of semantic communications and optimize the system’s performance. We also validate our approach through a real wireless channel prototype using software-defined radio (SDR). To the best of our knowledge, this is the first investigation of the fundamental workings of a semantic communications system, accompanied by the pioneering hardware implementation. To facilitate reproducibility and encourage further research, we provide open-source code, including neural network implementations and LabVIEW codes for SDR-based wireless transmission systems.
Why This Matters
At the time, many semantic communication papers showed performance gains without explaining the internal behavior of the learned encoder and decoder. This paper tries to open that black box. It asks which parts of the network behave like source coding, which parts behave like denoising, and why transformers may help image semantic communication.
The prototype matters for the same reason. A model that works only in AWGN simulation is not enough evidence for a wireless communication system. The SDR testbed checks whether the observed architecture advantage survives real channel effects such as gain mismatch, reflections, DAC quantization, and I/Q imbalance.
What This Paper Does
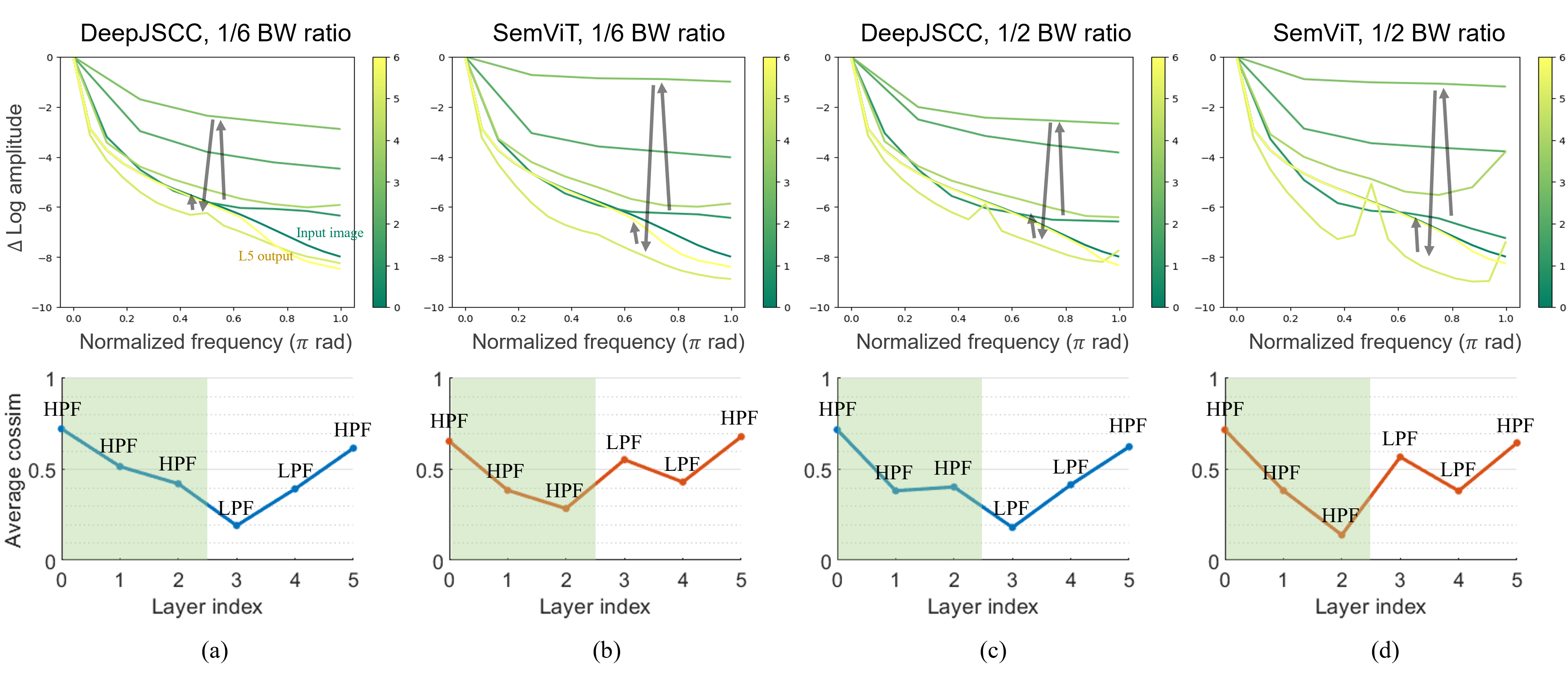
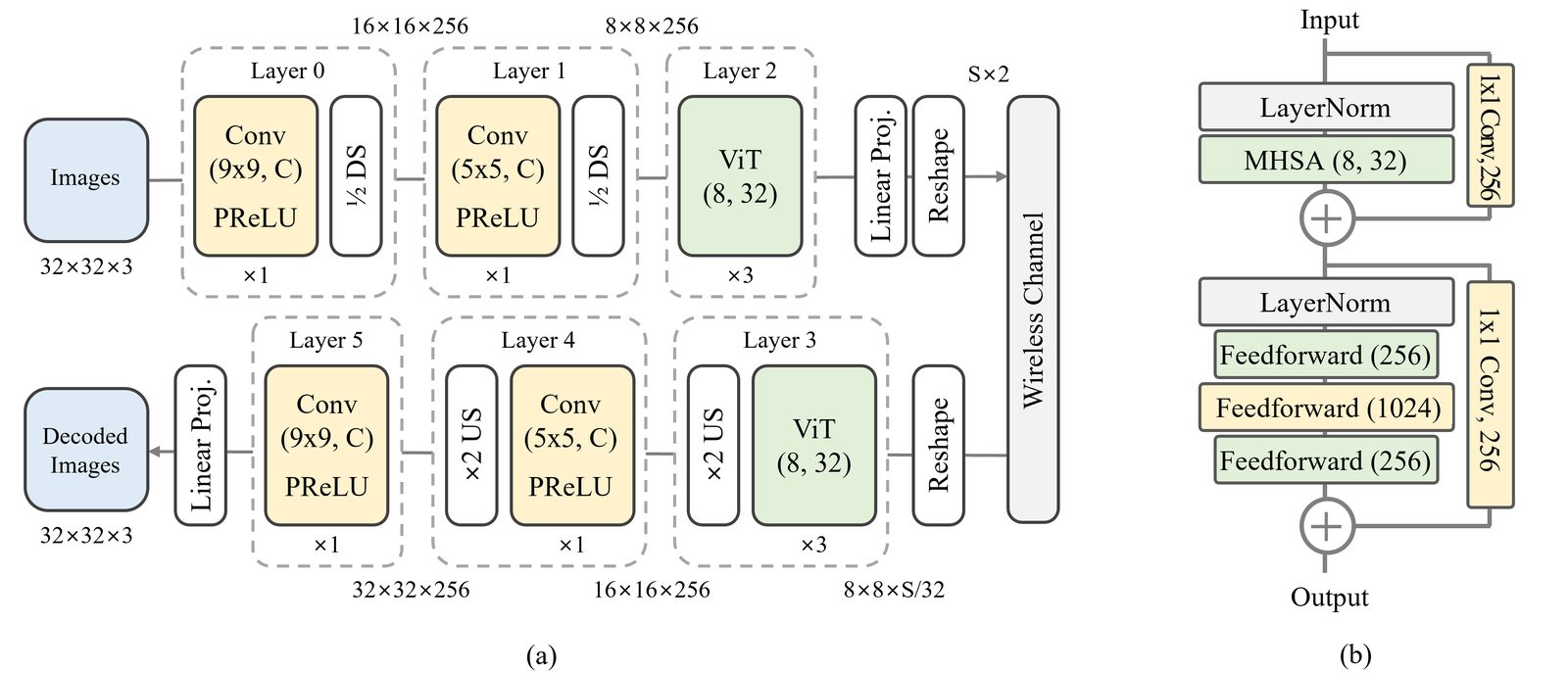
The paper starts from a CNN-based DeepJSCC baseline and selectively replaces middle layers with ViT blocks. The best model uses ViT blocks at the semantic bottleneck and early decoder side, matching the intuition that transformers help diversify compressed features and act as strong low-pass filters during reconstruction.
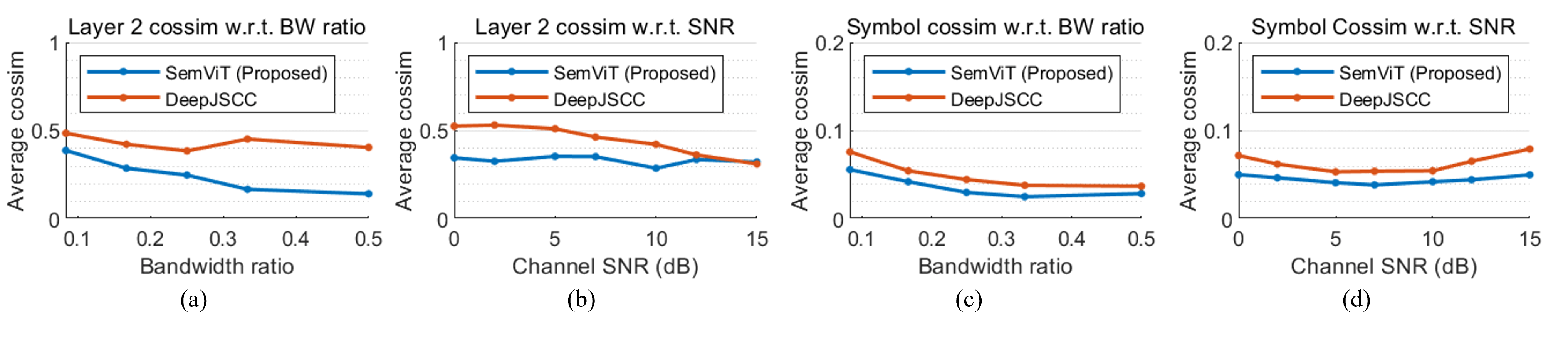
The analysis has two main tools. Average cosine similarity measures how diverse or redundant learned features are, while Fourier analysis shows whether each layer behaves more like a high-pass or low-pass transformation. Together they support a simple interpretation: encoders tend to extract and diversify high-frequency information, while decoders suppress channel noise and reconstruct image structure.
Key Results
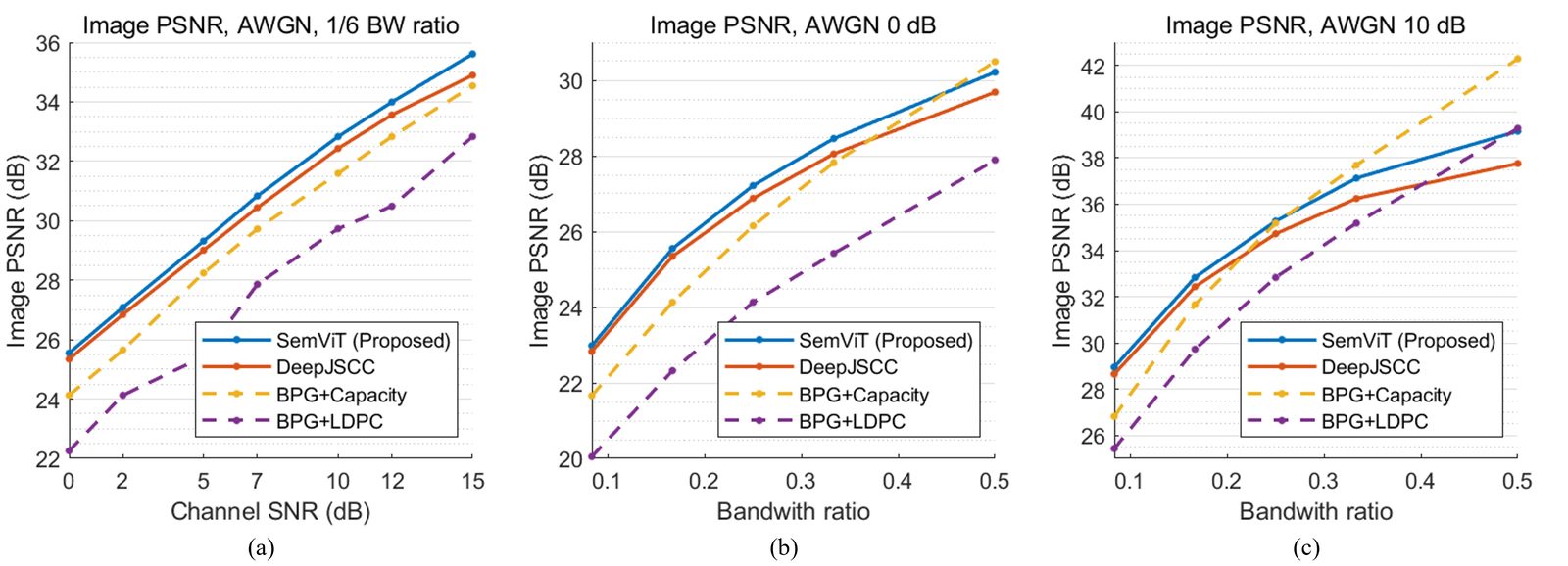
- SemViT outperforms CNN-based DeepJSCC across AWGN, Rayleigh, and measured wireless conditions.
- The PSNR gap grows in higher-SNR and higher-bandwidth-ratio regimes, where better source coding becomes more important.
- ViT blocks diversify latent representations and show strong low-pass behavior in the decoder.
- Real wireless measurements show better quality than CNN baselines, while also exposing an approximately 3 dB simulation-to-prototype gap caused by non-Gaussian hardware/channel errors.
- The paper provides open-source neural and SDR code for reproducibility.