Symbol Distributions in Semantic Communications: A Source-Channel Equilibrium Perspective
why learned semantic symbols become heavy-tailed and how to regularize them.
Abstract
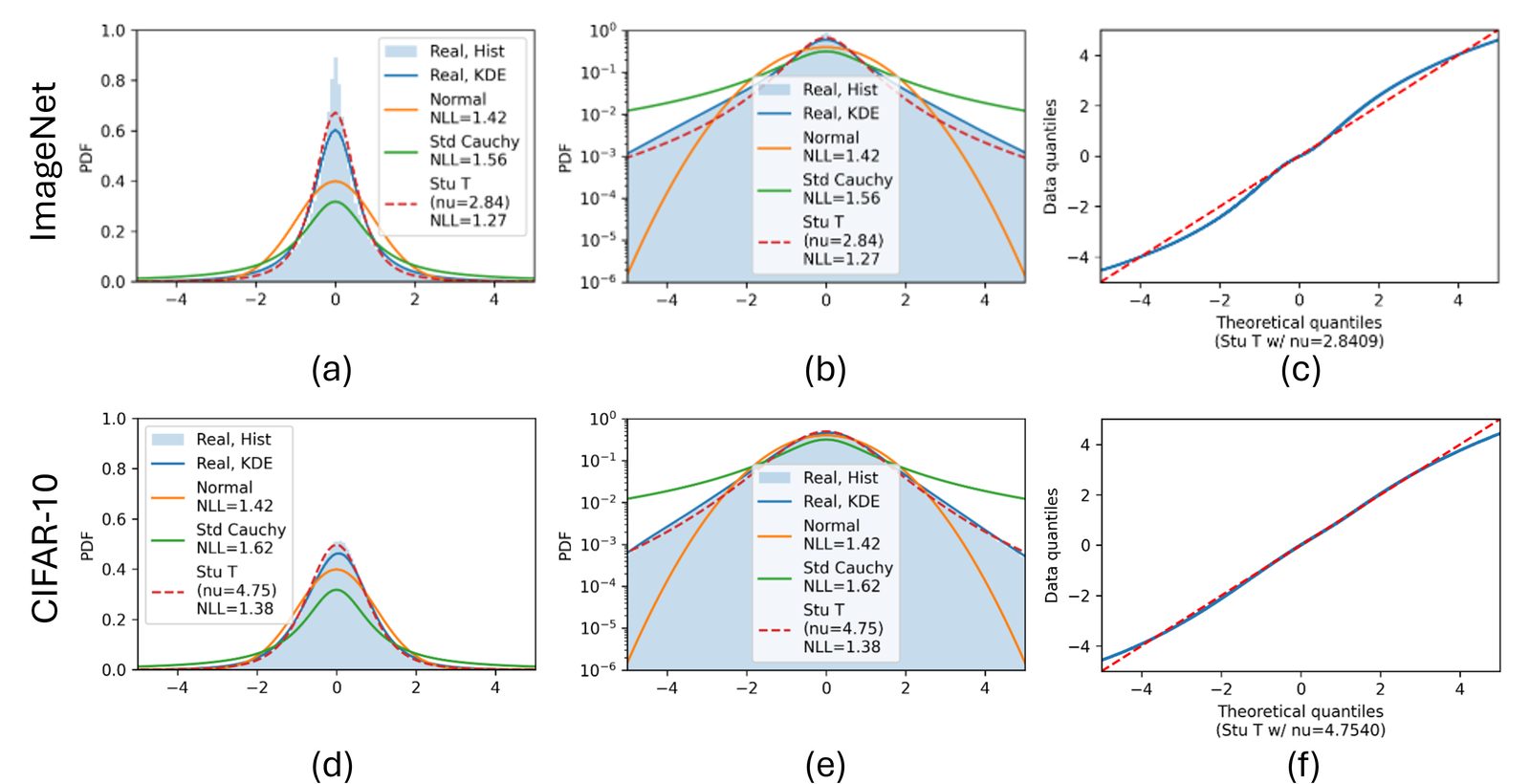
Semantic communication systems often use end-to-end neural networks to map input data into continuous symbols. These symbols, which are essentially neural network features, have fixed dimensions and often exhibit heavy-tailed distributions. However, the mechanism behind this distributional shape remains underexplored due to the end-to-end nature of encoder training, hindering systematic analysis and design. In this paper, we propose a parametric model for semantic symbol distributions. We model end-to-end training as inducing two coupled pressures on the symbol distribution: a source pressure that favors power allocation minimizing the average description cost, and a channel pressure that favors distributions with higher channel utilization. Under surrogate objectives that capture these effects, we obtain a Student’s t-distribution as a model for the semantic symbols. Experiments on image-based semantic systems show that the model closely predicts how the shape parameter varies with (i) explicit symbol rate control and (ii) dataset entropy variability. Furthermore, enforcing a target symbol distribution via regularization (e.g., a Gaussian prior) improves training convergence, which is consistent with our hypothesis.
Why This Matters
Semantic communication systems are usually evaluated by reconstruction quality, while the transmitted symbols are treated as a black-box by-product of training. That is a problem for deployment. Symbol statistics determine entropy, peak behavior, fronthaul compressibility, RF stress, and how well the learned interface matches a physical channel.
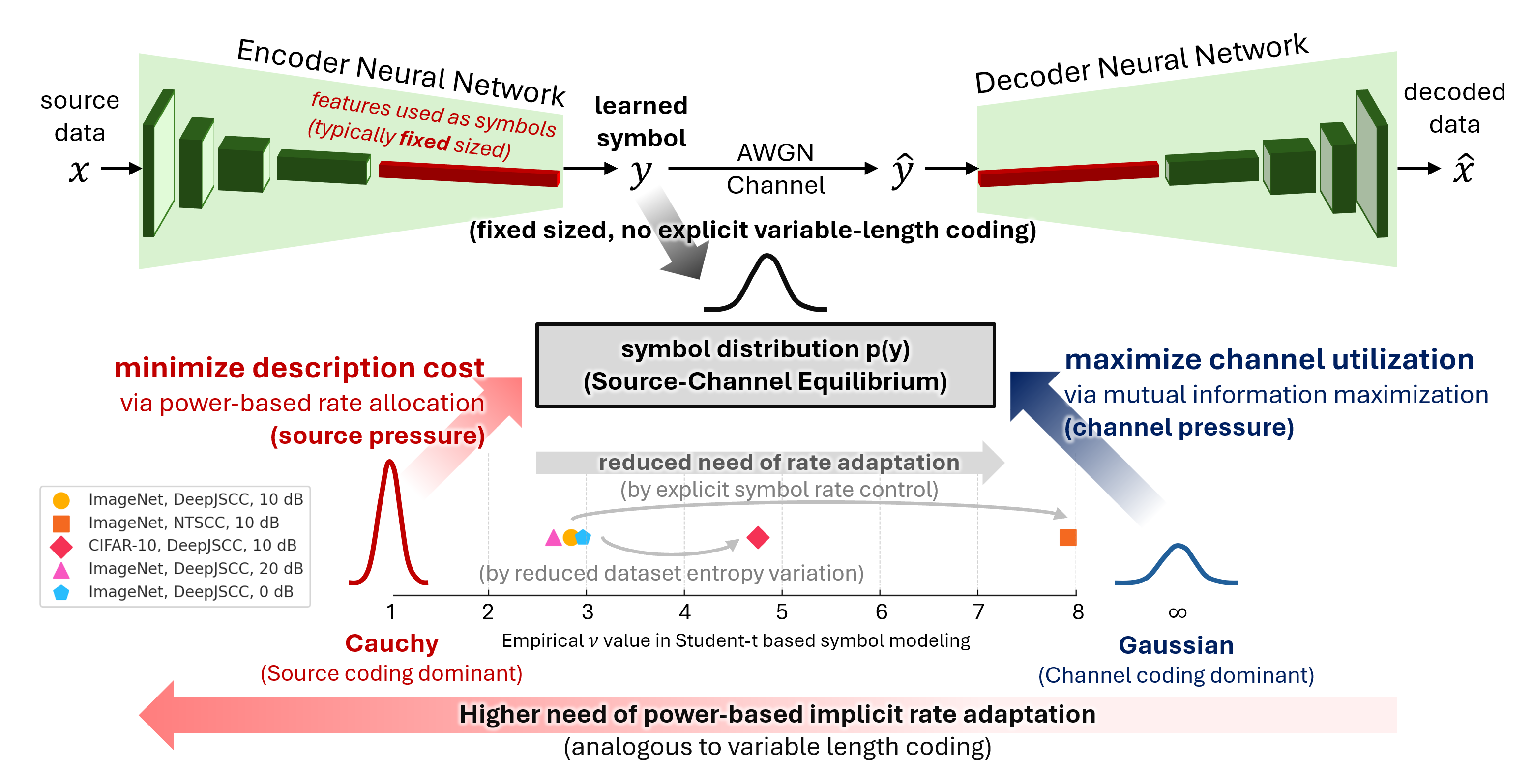
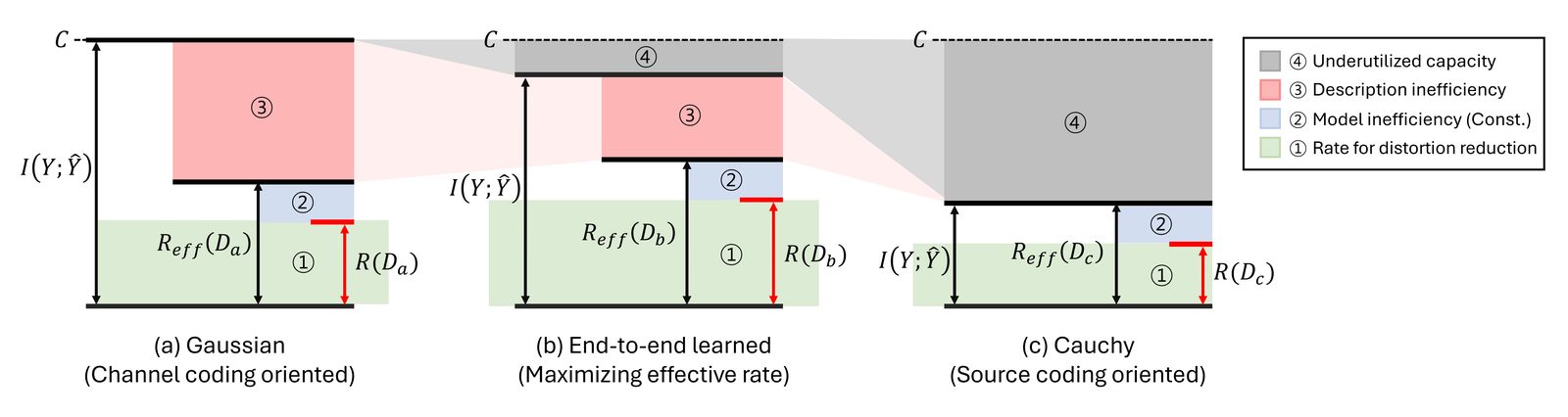
This work makes those statistics analyzable. It separates two forces that are usually entangled in end-to-end training: channel pressure, which prefers high-entropy channel-useful symbols, and source pressure, which prefers energy allocation that behaves like implicit variable-length coding.
What This Paper Does
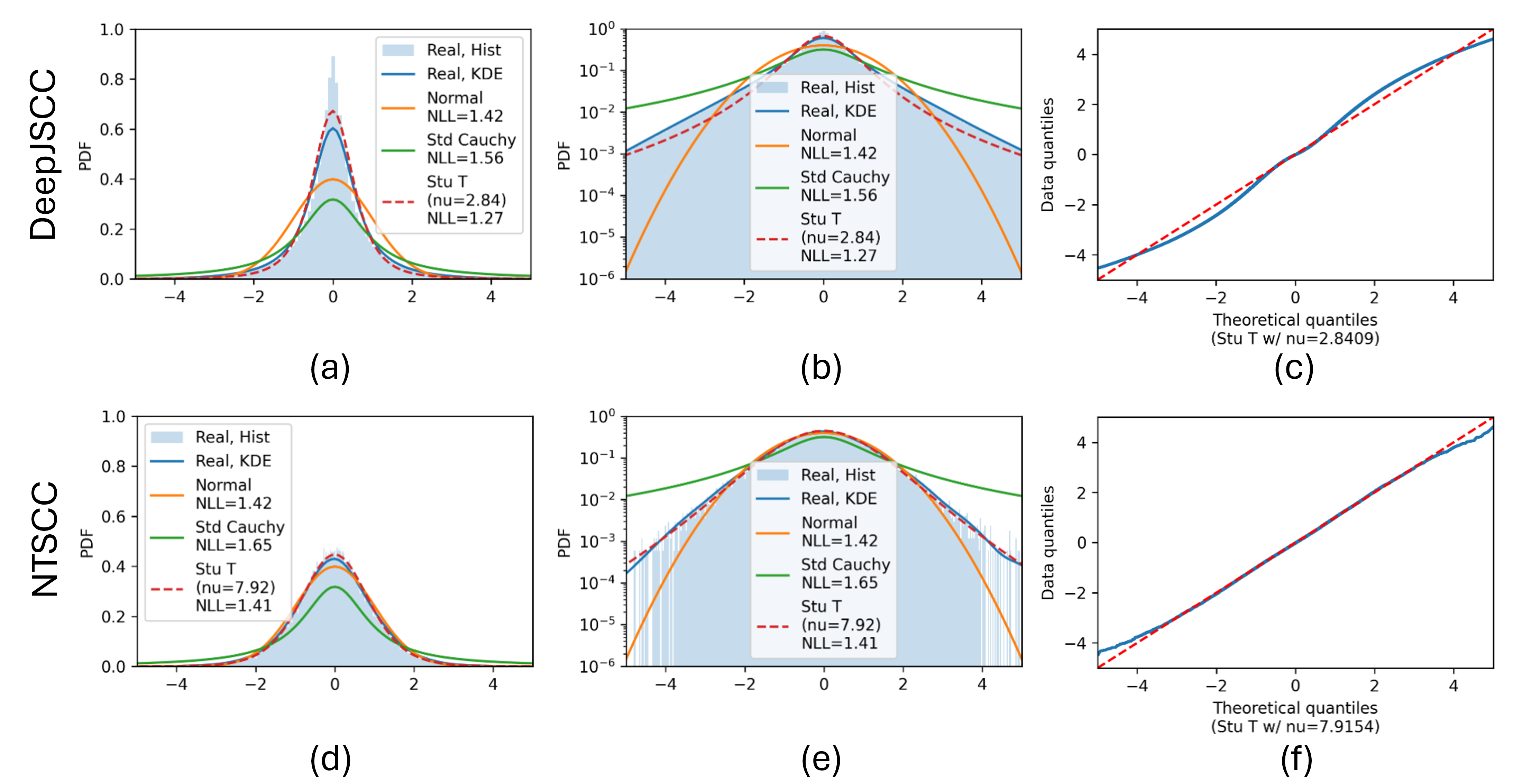
The paper derives a Student-t symbol model from a source-channel tradeoff and validates it on image semantic communication systems. DeepJSCC, which has a fixed symbol budget, produces heavier-tailed symbols because it must adapt through symbol amplitudes. NTSCC, which has explicit symbol-rate control, shifts closer to a Gaussian-like regime because part of the rate adaptation is handled structurally.
The same logic explains dataset effects. ImageNet has much larger image-to-image entropy variability than CIFAR-10, so fixed-length transmission benefits more from implicit rate adaptation and learns heavier tails. CIFAR-10 is more uniform, so the learned distribution is closer to Gaussian.
Key Results
- The learned symbol distribution is well described by a variance-normalized Student-t family.
- Explicit symbol-rate control pushes symbols toward larger
nu, i.e., a more Gaussian-like regime. - Larger sample-to-sample source entropy variability pushes fixed-length systems toward heavier tails.
- Training SNR changes the fitted tail behavior, showing that the channel condition also shapes the latent law.
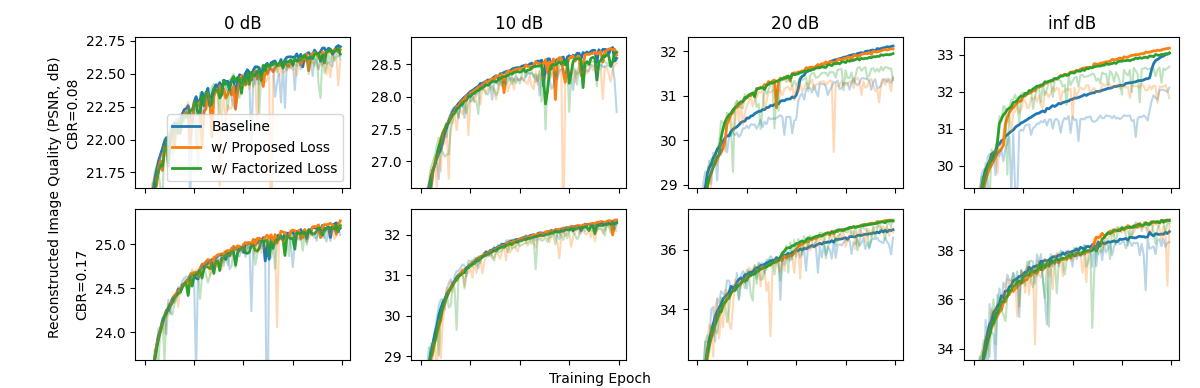
- A weak Gaussian-prior regularizer improves convergence in source-coding-dominated regimes, supporting the idea that distribution shaping affects training dynamics.