Back to the Bits: Parametric Symbol Compression for Semantic O-RAN Fronthaul
semantic symbol compression for practical O-RAN fronthaul deployment.
Abstract
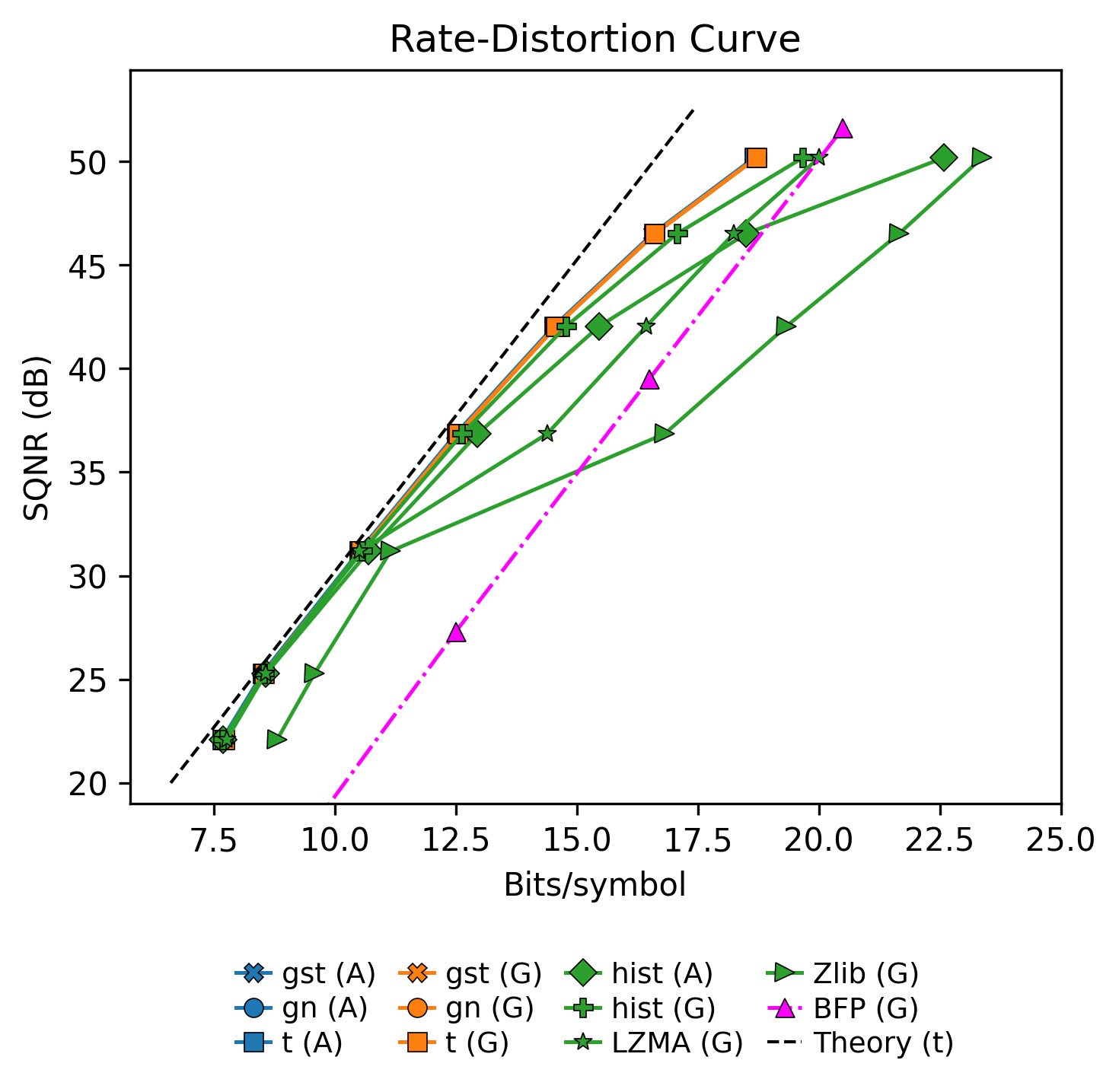
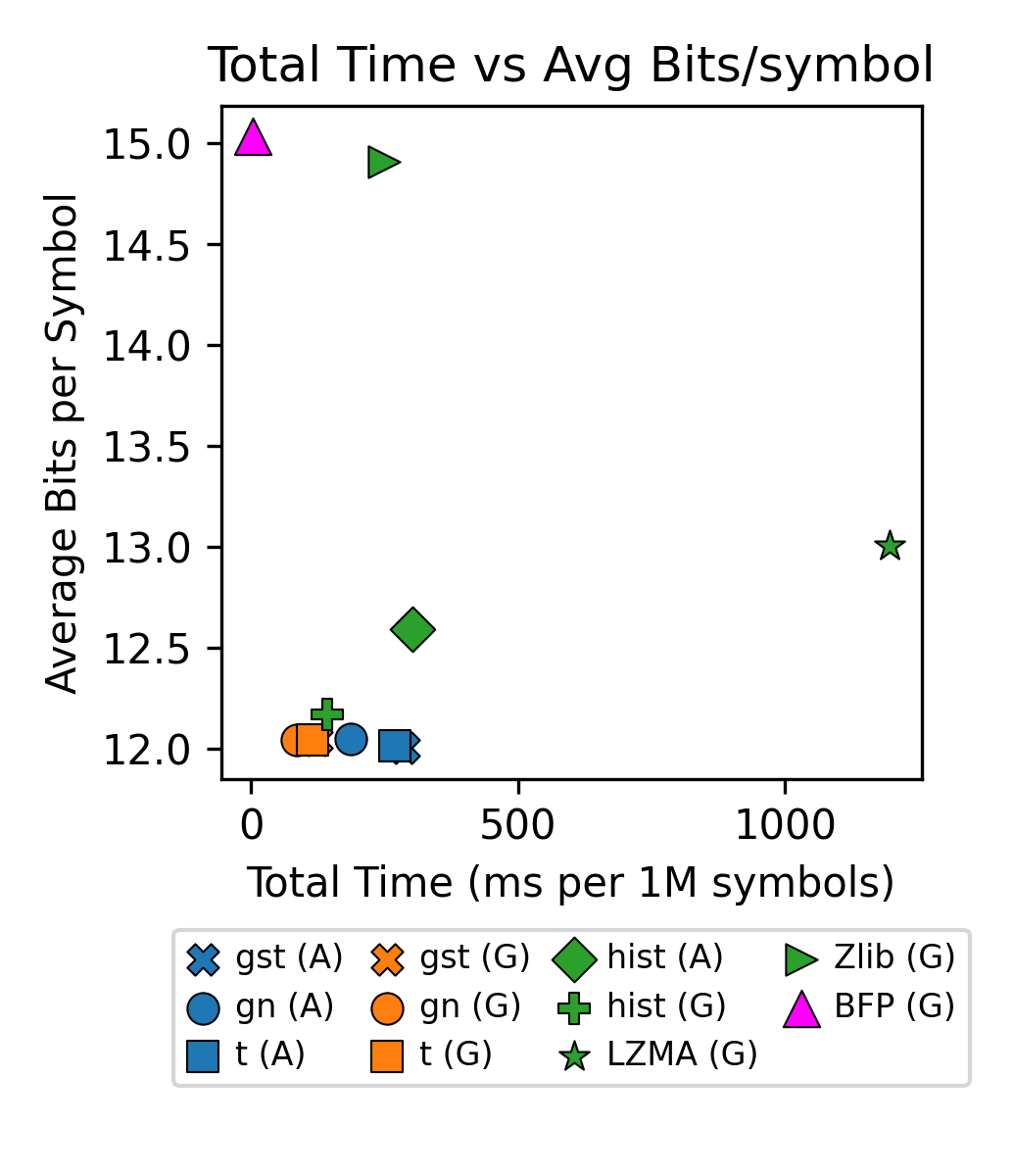
Semantic communication systems such as DeepJSCC convert input data into complex-valued I/Q symbols for efficient end-to-end transmission. In many practical deployments, these symbols must be further compressed into bits for fronthaul transport to radio units (RUs), which often lack neural network capabilities and have limited hardware resources. Yet, compression of semantic symbols for fronthaul has been understudied. In this paper, we present a lightweight parametric symbol compression scheme that models the symbol distribution using a (generalized) Student-t distribution and applies entropy coding based on this probability modeling. The receiver performs only probability table reconstruction and entropy decoding, making the method suitable for deployment on non-neural, low-power devices. Experimental results show that the proposed coder reduces rate by 19-19.2% vs. zlib and 7.2-7.6% vs. LZMA. It also provides an additional 19.1-20.2% rate reduction over a block floating-point baseline used in O-RAN fronthaul compression profiles. In runtime, it yields end-to-end codec speedup gains of up to ~2.9x over zlib and ~4.2-14.1x over LZMA.
Why This Matters
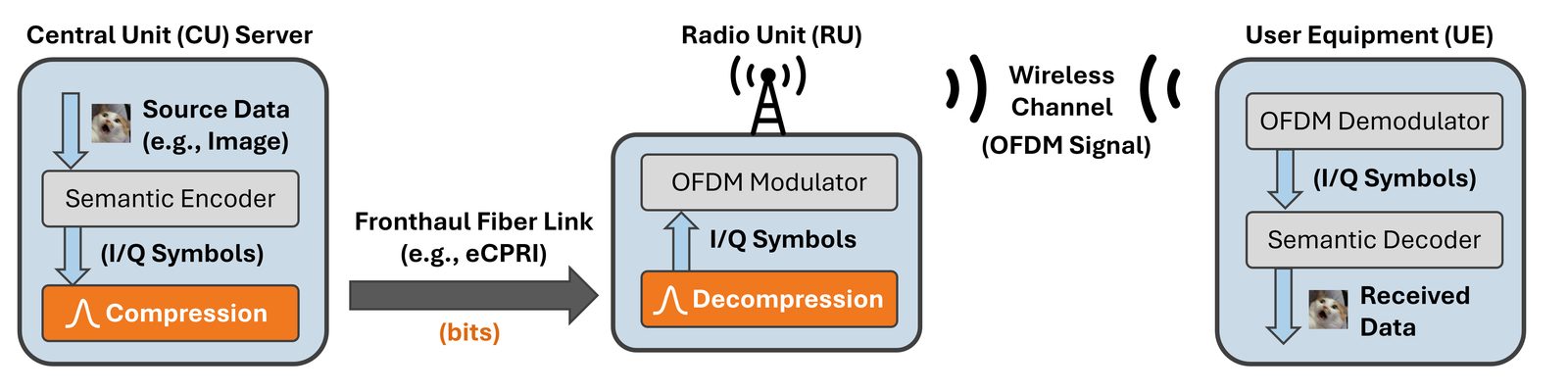
Most semantic communication papers stop at the learned encoder output, but O-RAN deployment does not. If the RU is simple, the fronthaul cannot assume another neural transform just to compress semantic latents. A useful codec must reduce rate, preserve semantic quality, and add only small side information.
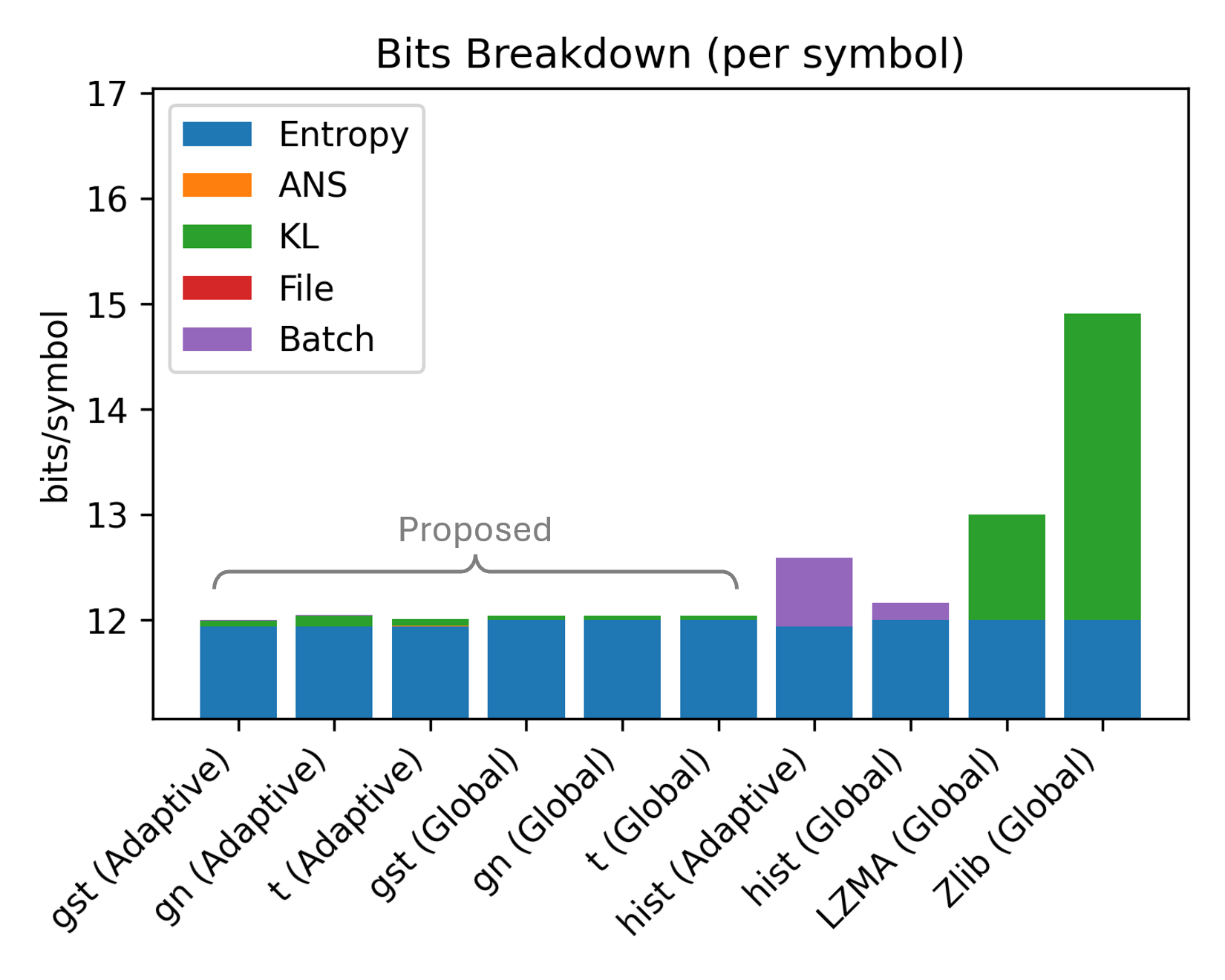
This paper uses the distributional structure of semantic symbols directly. Since semantic latents are continuous-valued and heavy-tailed, generic byte-wise compressors such as zlib and LZMA miss symbol-level probability information. Block floating-point compression is also limited because it scales blocks but does not entropy-code according to the actual symbol law.
Key Idea
The method extends the spirit of modulation compression from finite constellations to neural semantic latents. Instead of sending a QAM constellation index, it sends quantized semantic-symbol indices under a compact fitted distribution. The probability model is small enough to describe with a few header bits per pack, but accurate enough to keep the cross-entropy close to the empirical source entropy.
Key Results
- Parametric symbol coding beats byte-wise dictionary compressors because it models the quantized semantic-symbol PMF directly.
- Student-t gives the best rate-latency balance; generalized Student-t is more robust when the empirical distribution deviates from a pure Student-t.
- Global fitting is preferable when latency dominates, while adaptive per-pack fitting is preferable when rate is the main constraint.
- Compared with BFP, the proposed codec gains rate by using entropy coding rather than only block-wise scaling.
- The method keeps inference-time neural complexity out of the RU.